Im Rahmen des Forschungsprojektes LEDS sollen natürlich nicht nur Methodiken zum Sammeln von semantischen Daten erforscht und gefunden, sondern auch praktische Anwendungsfälle entwickelt werden.
Verantwortlich für diesen Bereich ist die Internetagentur Netresearch. Sie betreut seit 18 Jahren Kunden beim Aufbau ihrer Internetpräsenz. Dabei hat sie sich auf die beiden Open Source Systeme Magento und TYPO3 spezialisiert. Netresearch will in verschiedenen Use Cases Linked Open Data (LOD) in E-Commerce Systeme einbinden, um die Usability und die Funktionen des Shops aus Sicht des Händlers und der Kunden durch die Einbindung von LOD zu verbessern.
Nachfolgend stellen wir alle 5 Use Cases vor, welche im Rahmen von LEDS umgesetzt werden sollen.
Use Case 1: Business Data Integration
Insbesondere Unternehmen mit gewachsener IT-Infrastruktur setzen eine Vielzahl der unterschiedlichsten Systeme verschiedener Hersteller ein, die untereinander gar nicht oder nicht nachhaltig integriert sind. Durch die mangelhafte Integration ist es oft nötig, eine sogenannte Middleware einzusetzen, um die Systeme miteinander zu verbinden. Solche Middlewares können häufig nicht mit der Entwicklung der einzelnen Systeme Schritt halten und schaffen zusätzliche Abhängigkeiten, welche die Updatefähigkeit und damit die Weiterentwicklung und Anpassung der IT-Infrastruktur behindert. Außerdem ist die Entwicklung individueller Middleware Lösungen kostenintensiv.
Eine mögliche Lösung hierfür wäre die Business Data Integration. Semantische Datenformate können von den verschiedenen Systemen als gemeinsames Datenformat zum Austausch genutzt werden. Die Modellierung und Anreicherung der Daten könnte so von den Anwendungen entkoppelt werden. Es wären lediglich Konnektoren für die einzelnen Systeme notwendig, die deren Datenstrom in semantische Formate bzw. zurück konvertieren. Da entsprechende Systeme häufig standardmäßig Im- und Exportschnittstellen für generische Formate wie CSV oder XML mit sich bringen, könnten diese als Quell- und Zielformate genutzt werden. Dadurch lässt sich eine spezifische Anpassung der jeweiligen Systeme vermeiden.
####Funktionsschema Linked Enterprise Data Integration
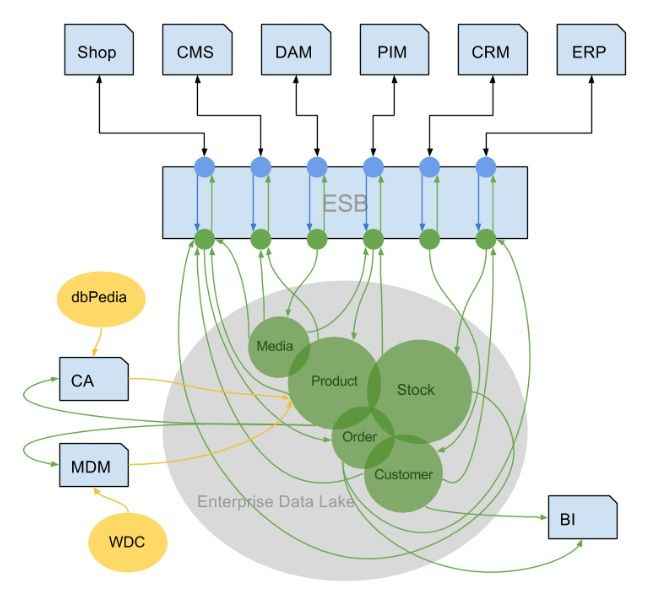
In der Abbildung sind die monolithischen Einzelsysteme über deren Im- und Exportschnittstellen mit dem Enterprise Service Bus (ESB) verbunden. Dieser nimmt die Transformation der eingehenden semistrukurierten Daten in strukturierte, semantische RDF-Daten vor und speist diese in einem Data Lake ein. Aus diesem wiederum ruft er mittels SPARQL-Abfragen die Daten aus dem Data Lake ab, die für das jeweilige System benötigt werden, transformiert sie in das jeweils benötigte Format und spielt sie zurück.
Aus dem Data Lake können sich neben dem ESB auch andere Anwendungen, wie die in der Grafik beispielhaft aufgezeigten Master Data Management (MDM), Content Augmentation (CA) und Business Intelligence Anwendungen bedienen bzw. Daten in selbigen eingeben.
Der Vorteil dieser Lösung gegenüber klassischen Middleware Lösungen besteht im Austausch der semi-strukturierten gegen strukturierte Daten. Während mit dem klassischen Ansatz die Daten nur von den Systemen genutzt werden können, die diese verstehen bzw. auf die sie Zugriff haben und die Integration jedes weiteren Systems weitere bzw. erweiterte Middleware erfordert, können nun beliebige Systeme auf beliebige Daten im Data Lake zurückgreifen. Damit kann die Systemlandschaft besser erweitert, gewartet und skaliert werden. Einzelsysteme sind im Bedarfsfall austauschbar. Durch das strukturierte Datenformat können zudem Daten aus externen Datenquellen unkompliziert in den Data Lake eingebracht werden.
Use Case 2: Content Augmentation
Der Use Case Content Augmentation soll insbesondere Redakteuren die Arbeit erleichtern. Die Verarbeitung meist unstrukturierter Daten und deren Prüfung auf Aktualität ist besonders arbeitsintensiv und langwierig. Sowohl die Schnelligkeit der Text-Erstellung, als auch deren Qualität stellt im E-Commerce jedoch einen geschäftskritischen Faktor dar. Über automatische Prozesse während der Texterstellung könnten somit Aufwände gesenkt und Wettbewerbsvorteile geschaffen werden.
Die Arbeit der Redakteure soll über eine teil- oder vollautomatische Einbeziehung zusätzlicher Inhalte aus Hintergrundwissensdatenbanken zu bestehenden Ontologien, ggf. unter Einbeziehung von Trending Topics auf Suchmaschinen und im Social Media erleichtert werden. Praktisch bedeutet dies, dass Redakteure ihre Eingaben mit Hintergrundwissen aus semantischen Datenquellen auf Basis gemeinsamer Ontologien verknüpfen, sodass dieses dann voll- oder teilautomatisiert eingebunden und für weitere Prozesse genutzt werden können. Das Hintergrundwissen ist anschließend vielfältig einsetzbar und kann bspw. paraphrasiert zur automatisierten Anreicherung bestehender Texte genutzt werden. Zusätzlich ist die automatisierte Erstellung von Landing Pages denkbar, die entsprechend der gemeinsamen Analogien auf den eigentlichen Text zurückverweisen. Die Ontologien können auch zur Verknüpfung der Texte untereinander, z.B. für Vorschläge zum Weiterlesen oder auf Basis gemeinsamer Ontologien mit aktuell aufstrebenden Themen in sozialen Netzwerken, verwendet werden. Zu letzteren könnten darüber hinaus automatisch Beiträge mit Hinweisen auf passende Texte in selbigen veröffentlicht und damit deren Sichtbarkeit gesteigert werden.
Daneben können die Hintergrundinformationen auch unterstützend beim Schreiben von Texten genutzt werden, indem passende Informationen bereits während des Schreibens in einer Sidebar neben dem Texteditor angezeigt werden.
Use Case 3: Master Data Management
Die Konzeption und Modellierung von Produktdaten ist ein aufwändiger Prozess, der Fachkenntnis sowohl in den Bereichen Shop- und Content-Management und Marketing als auch im jeweiligen Themenfeld der Produkte erfordert. Fehler bei der Datenanlage bzw. -pflege können zu schlechter Auffindbarkeit in Suchmaschinen und zu hohen Abbruchraten der Nutzer im Shop führen. Hierbei kann die Nutzung semantischer Daten helfen.
Basierend auf semantischen Produktinformationen im Netz können dem Redakteur Attribute bzw. Attributgruppen empfohlen werden. Diese Empfehlungen stammen aus den semantischen Produktdaten anderer Shops, die wiederum aus einer entsprechenden Datenquelle wie z.B. dem Web Data Commons Dataset ermittelt wurden. Grundlage für die Suche nach passenden Produkten und deren Klassifikation kann, sofern auffindbar, das Produkt selbst oder dessen Produktklasse sein. Wurden gleiche oder vergleichbare Produkte im semantischen Netz gefunden, sollten dem Redakteur die Produktmerkmale, deren Wertelisten und ggf. auch Werte sowie Relationen zu anderen Produkten vorgeschlagen werden. Diese kann er dann selektiv annehmen, ablehnen und bearbeiten.
Vorteil dieser Lösung wäre v.a. die Zeitersparnis bei der Klassifizierung und Pflege von Produktdaten. Gegenüber bestehenden Klassifizierungssystemen besteht der Vorteil v.a. darin, dass die Klassifizierung freier und weniger abhängig von den jeweiligen Konsortien ist.
Use Case 4: Semantic Search
Herkömmliche Suchmechanismen basieren auf der Verschlagwortung von unstrukturierten Texten, wobei in der Regel auch deren Wortstämme auf Basis der Sprachsyntax indexiert werden. Der Suchbegriff wird anschließend auf die gleiche Weise in Schlagworte heruntergebrochen, für die dann passende Schlagworte aus dem Index gesucht werden. Dieses Vorgehen führt häufig dazu, dass ähnliche Begriffe und Synonyme bei der Suche nicht erkannt werden. Desweiteren erfordert eine systemübergreifende Suche meist einen hohen Integrationsaufwand.
Über die Semantic Search sollen die Schlagworte mit Hintergrundwissen bspw. aus der Open Data Cloud oder anderen Datenquellen angereichert werden und für das Matching der Suchbegriffe mit den Schlagworten herangezogen werden. So könnte bspw. bei einer Suche nach “Matchbox” erkannt werden, dass es dabei um die Marke selbst, aber möglicherweise auch grundsätzlich um Spielzeugautos geht. Bietet der Händler nun keine Matchbox, dafür aber Spielzeugautos anderer Hersteller an, könnten sie im Gegensatz zur reinen schlagwortbasierten Suche gefunden werden.
Use Case 5: Recommendation Engine
Um Benutzern auf Online-Plattformen weiterführende bzw. ähnliche und passende Angebote anbieten zu können, müssen die Beziehungen zwischen den Seiten bzw. Artikeln entweder manuell hinterlegt oder in mehr oder weniger aufwendigen und erfolgreichen Algorithmen gefunden werden. Dies führt zu einem entweder hohen redaktionellen Aufwand oder zu geringen Trefferquoten und damit zu höheren Absprungraten.
Wie bei der Semantic Search kann auch eine Recommendation Engine das Hintergrundwissen zu den Entitäten nutzen, um passende Entitäten nach bestimmten Regeln vorzuschlagen. Dabei wäre auch diese nicht auf die Daten aus dem Ursprungssystem selbst (z.B. Shop oder CMS) beschränkt, sondern könnte Daten aus allen Systemen am Data Lake als Vorschläge oder aber zur Generierung der Vorschläge heranziehen. So könnten bspw. ähnliche Interessen aus Verlaufsdaten im CRM oder Cross-Selling-Vorschläge aus den Verkaufszahlen im ERP ermittelt werden.