Martin Voigt, CEO der Ontos GmbH und Medieninformatiker mit einem PhD in den Schnittstellen von Web Engineering, Semantic Web und Information Visualization, weiß, wie mühsam die Lektüre vieler Dokumente ist. Deshalb möchte er mit neuen Natural Language Processing-Technologien (NLP) sicherstellen, dass wir in Zukunft keine großen Dokumentenmengen mehr durchsuchen müssen, um die wirklich relevanten Informationen zu erhalten. Lieber will er uns einen verständlichen Überblick ermöglichen, der trotzdem über ausreichend Detailtiefe verfügt. Mit der Ontos GmbH arbeitet er deshalb tagtäglich auf dem spannenden Feld der Deep Learning-Methodik und steckt über beide Ohren in einer Vielzahl deutscher und europäischer Forschungsprojekte. Im Rahmen des Verbundprojekts Linked Enterprise Data Services (LEDS) leitet Martin das Arbeitspaket ASP-C, dass sich mit den Herausforderungen der Informationsextraktion beschäftigt. Wenn Martin die NLP-Technologien für sich ganz allein nutzen dürfte, würde er gerne mal die Zusammenhänge zwischen den Nebenwirkungen auf Beipackzetteln mehrerer Medikamente sowie die Zusammenhänge zwischen Gesetzestexten und dem Lobby-Einfluss der Großkonzerne explorieren. Zugegeben, das würde uns auch sehr interessieren. Also Martin, sag uns Bescheid, wenn die Auswertung vorliegt.
Was ist der Status Quo bei der Nutzung von Natural Language Processing? Gibt es konkrete funktionierende Produkte und Anwendungen?
Natural Language Processing (NLP) ist einerseits schon sehr lang Gegenstand von Forschung und Entwicklung und andererseits sehr breit aufgestellt. Einen guten Überblick zur Breite des Forschungsgebiets erhält man u.a. in „Survey of the State of the Art in Human Language Technology“ von Cole et al. Vereinfacht gesagt, geht es bei NLP darum, wie ein „Computer“ die natürliche, menschliche Sprache, z.B. Deutsch, Englisch oder Japanisch, verarbeiten und verstehen kann – egal für welchen Zweck. Sehr oft wird NLP synonym mit Computational Linguistics (CL) verwand. Hierbei handelt es sich mehr oder weniger um dasselbe Thema, wobei Anhänger von NLP eher praktisch orientiert sind. NLP Forschungsbereiche sind etwa die geschriebene und gesprochene Sprachein- sowie ausgabe, verschiedene Formen der Informationsextraktion aber auch die Evaluation der verschiedenen Systeme. Die jahrelange Entwicklung ist natürlich auch im täglichen Gebrauch angekommen, heute mehr denn je.
Bekannte Beispiele sind
- Erkennung von (Hand-)Schrift in Bildern / Scans bzw. auf mobilen Endgeräten (OCR), um so eine effiziente maschinelle Weiterverarbeitung zu ermöglichen.
- Virtuelle, sprachgesteuerte Assistenten auf (mobilen) Endgeräten, wie Siri, Google Now oder Cortana, mit denen bspw. die Spracheingabe das mühesame Schreiben von Suchanfragen ersetzt.
- On-the-fly Übersetzung von geschriebener und gesprochener Sprache in Skype.
- Extraktion von Meta-Informationen, wie Personen und Produkte sowie deren Zusammenhänge aus Texten, die u.a. für eine verbesserte, semantische Suche genutzt werden können.
Was wird NLP in 5-10 Jahren im Alltag ermöglichen?
Durch neue Möglichkeiten des maschinellen Lernens, semantischer Technologien und auch besserer und deutlich günstigere Hardware werden wohlmöglich folgende Technologien in den Alltag einkehren.
- Echtzeitübersetzungen für die meisten natürlichen Sprachen, auch mit Domänen-spezifischen Vokabular
- Automatisches Zusammenfassen großer Dokumente oder gar von Dokumentenmengen, verfasst in mehreren Sprachen, zu kurzen aber hochwertigen Essays.
- Automatisiertes Schreiben von qualitativ hochwertigen (Nachrichten-) Texten auf Basis von strukturierten Daten und anderen Texten
- Hochwertiges, maschinelles, natürlich-sprachiges Antworten auf Wissensfragen für jedermann
- Erkennen der Stimmung eines Menschen sowie von Ironie und Sarkasmus
- Steuerung vieler Maschinen mittels Spracheingabe
- Durch bessere Hardware und fortgeschrittene Technologien können viele der NLP-Anwendungen allein auf Smartphones, virtuellen Brillen oder anderen Wearables ausgeführt werden.
Welchen Herausforderungen steht man aktuell noch gegenüber?
Aufgrund der Breite des Forschungsfeldes NLP kann an dieser Stelle nur schwierig eine übergreifende Aussage gemacht werden, welche Forschungsfragen im Detail zu lösen sind. Das würde den Rahmen sprengen und kann ich hier nur im Rahmen der nächsten Frage beantworten. Abgesehen von technologischen Details ist jedoch vor allem eine verbesserte Zusammenarbeit zwischen den Domänen Computational Linguistics bzw. Natural Language Processing, Semantic Web, Machine Learning und Human Computer Interaction notwendig. Es gibt zwar vereinzelte multidisziplinäre Forschungsprojekte, jedoch kochen viele der Forschergruppen noch ihr eigenes Süppchen.
Welchen dieser Herausforderungen stellt sich das LEDS-Projekt? Und wie?
Im Forschungsgebiet der semantischen Informationsextraktion werden die folgenden Herausforderungen gesehen, die auch im Projekt LEDS angegangen werden.
Ablösung von regelbasierten NLP-Systemen durch Deep Learning
Unser Hauptziel - wie es auch durch Ontos vorangetrieben wird - ist die verbesserte, effiziente Übertragbarkeit des NLP-Ansatzes zur Informationsextraktion zwischen verschiedenen Domänen und auch Sprachen - ohne das dazu mühsam tausende, teils fixe Regeln definiert bzw. adaptiert werden müssen. Vergleichbar zu Lösungen von Softwarekonzernen wie Google, Facebook oder Microsoft, werden hierzu neue Möglichkeiten des maschinellen Lernens, speziell Deep Learning (DL) auf das Problemfeld übertragen.
Dessen Vorteile sind:
- Immense Einsparung von Ressourcen: Bisher war sehr viel Handarbeit notwendig, um die Regeln zu erstellen und Trainingsdaten aufzuarbeiten. Und dieser Manuelle Aufwand musste je Sprache und Domäne wiederholt werden. Es sind Linguisten notwendig, um die notwendigen Modelle zu erstellen und zu warten. Dies kann durch DL wesentlich reduziert werden.
- Hohe Robustheit: Bisherige Ansätze legen die Erkennung von atomaren Satzbestandteilen, den Phrasen, zugrunde. Dies ist oftmals nur mit hohem Aufwand möglich und gerade bei grammatikalisch schlechten Sätzen, wie sie z.B. im Social Web bestehen, ist die Fehlerrate hoch. Für DL ist dies nicht notwendig bzw. wird implizit gemacht.
- Adaptierbarkeit: DL-Modelle sind in der Regel in Schichten angeordnet, so dass je nach Notwendigkeit neue Funktionen geschaffen werden können. Für NLP bedeutet dies, dass bspw. Phrasen (Verb, Adjektiv,…), Wortklasse (Person, Produkt, Ort, …), Wortbedeutung (Jaguar/Tier und Jaguar/Auto) und schließlich die Bedeutung eines Dokuments erschlossen werden kann. Künftig kann diese Technologie sogar dazu verwendet werden, automatisch auf menschliche Fragen natürlichsprachlich zu antworten, was durch erste Forschungsarbeiten bereit gezeigt wurde.
- Kundenorientiert: Auf der Basis der DL-Modelle können Kunden auf einfache Art und Weise Erweiterungen hinzufügen. Dies bedeutet, dass eigene neue Konzepte, wie Produkt, Gesetz, …, hinzugefügt und mittels „supervised learning“ dem System beigebracht werden. Durch diesen Ansatz kann der Kunden das System auf eigenständig auf seine Bedürfnisse anpassen.
Fakten-basierte Extraktion von Informationen
Bei den heutigen Werkzeugen steht im Vordergrund, vor allem Entitäten von verschiedenen Konzepten zu extrahieren. Folgendes Beispiel soll dies verdeutlichen. „Adam Neumann is the CEO of super-hot office rental company WeWork, the most valuable startup in New York City.“ Es ist State of the Art hier die Entitäten “Adam Neumann” (Person), “WeWork” (Organisation) oder „New York City“ (Ort) aus dem Satz zu extrahieren. Durch die genannte DL-Technologie wollen wir es auch ermöglichen, effizient neue Konzeptarten, wie „CEO“ (Position) oder „super-hot“ (positives Sentiment), zu extrahieren. Das große Ziel von Ontos im Projekt LEDS ist jedoch der Folgeschritt: die Extraktion von Faktenwissen, d.h. Relationen zwischen den Entitäten, und das Generieren eines semantischen Netzwerkes aus den gewonnenen Informationen. Allein aus dem Beispielsatz können viele semantische Fakten gewonnen werden:
- „Adam Neumann“ hat_vornamen „Adam“ bzw. „Adam Neumann“ hat_nachnamen „Neumann“
- „Adam Neumann“ arbeitet_bei „WeWork“ in_position „CEO“
- „WeWork“ wird positiv_erwähnt als „super-hot“
- „WeWork“ sitzen in „New York City“
Hieraus wird deutlich, welche Menge an semantischen Informationen in einem durchschnittlichen Nachrichtentext mit ca. 3000 Wörtern liegen. Diese Informationen zur weiteren Verarbeitung, bspw. in intelligenten Suchen zur Verfügung zu stellen, ist ein wesentliches gemeinschaftliches Ziel in LEDS.
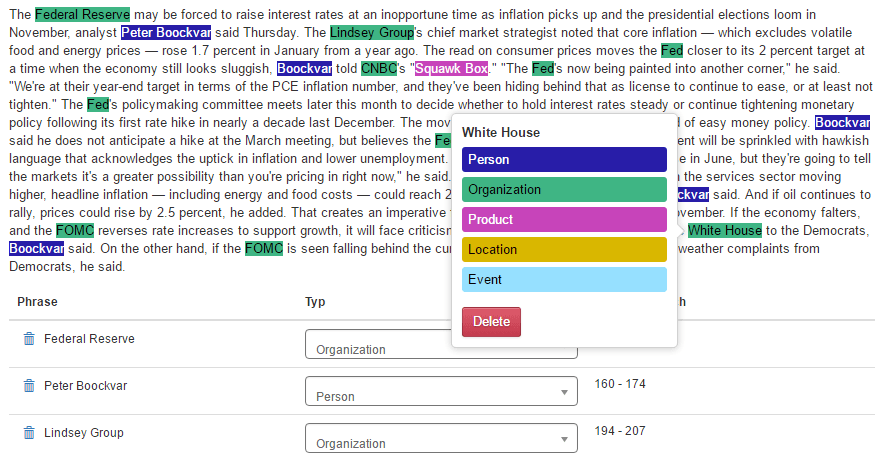
Abb. 1: Annotation von Named Entities verschiedener Typen, wie Person, Produkt oder Ort, in MINER’
Disambiguierung von Entitäten
Ein drittes Projektziel mit NLP-Bezug ist die Schaffung von Konzepten und Prototypen, um die eindeutige Bedeutung von gefundenen Entitäten herzuleiten. Ein einfaches Beispiel ist die unterschiedliche Schreibweise der deutschen Bundeskanzlerin je Sprache: Angela Merkel (DE), Ангела Меркель (RU) und Άνγκελα Μέρκελ (GR). Aber auch Abkürzungen, wie „DB“ müssen auf Basis des Kontexts bspw. auf „Deutsche Bahn“ oder „Deutsche Bank“ abgebildet werden. Hier wird technologisch einerseits auf das DL und andererseits auf semantische Technologien sowie die Linked Open Data Cloud gesetzt. Insbesondere die zuletzt genannten Ansätze werden auch im Projekt gezielt eingesetzt, um Information aus strukturierten (Datenbanken) und semistrukturierten Datenquellen (u.a. soziale Netzwerke) zu extrahieren und miteinander zu verknüpfen.
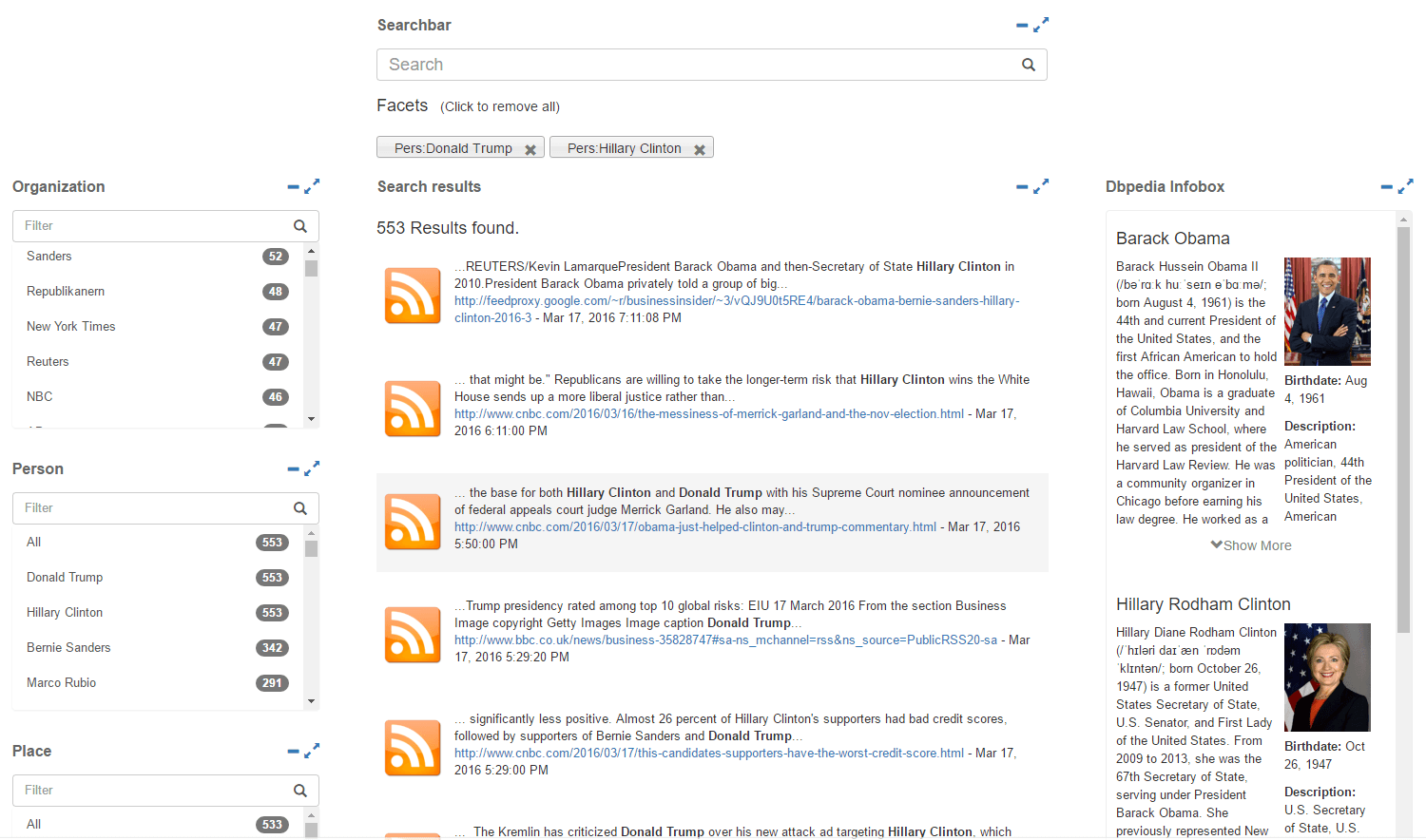
Abb. 2: Nutzung der gefundenen Entitäten zur zielgerichteten Suche sowie zur Anzeige weiterführender Informationen aus der Knowledge Engine DBpedia